You are the AI agent's harness
Most AI coding pipelines catch hallucinations after they happen. I built one that prevents them upstream — by treating the human as the harness.
TL;DR.
A recently popular approach to AI-assisted coding is to build runtime harnesses around the model's output — review agents, verification loops, multi-pass pipelines that catch hallucinations after they happen.
I went the other direction.
I built a pipeline that removes the model's decision latitude before code generation, so there's no room for hallucinations to enter in the first place. The runtime harness goes away. A different kind of harness takes its place, and that harness lives entirely upstream of the model's first token.
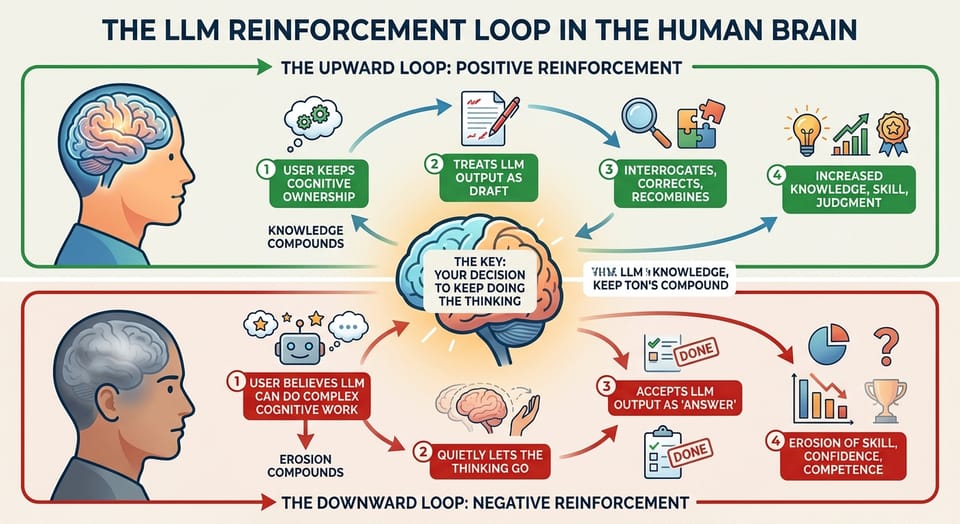
The argument of this post is that this upstream harness isn't really a piece of infrastructure. It's the engineer using it. In an LLM-assisted coding stack, you are the harness — your analytical work of decomposing problems, articulating constraints, and producing assertable acceptance criteria. The artifacts you build along the way (specs, rule files, conventions, profiles) are durable expressions of that work, but the harness itself is the human capacity that produces them. If the harness is good, the model's output is reliable. If the harness is poor, no amount of runtime checking saves you.
A hot topic in AI-assisted coding right now is to build sophisticated harnesses around what the language model produces at runtime:
- Review agents that catch hallucinations after they're generated.
- Verification loops that re-prompt the model when its output looks wrong.
- Multi-pass pipelines that take the model's first attempt, find the bugs, and feed corrections back in.
The premise is the same across the major tools and the open-source experiments alike: the model will sometimes be wrong, so you need apparatus to detect when it is.
I've spent the last several months going the other direction — building a pipeline that removes the model's decision latitude before code generation, so there's nothing left to catch downstream. I want to walk through how I got there. The path runs through a compiler analogy that turns out to be both useful and incomplete in interesting ways. Mostly incomplete.
The compiler analogy as a starting point
A compiler doesn't translate source code into machine code in one step. It runs multiple passes, each transforming the code into a more constrained intermediate representation than the last:
| Pass | Input | Output |
|---|---|---|
| Lexical analysis | Source code (raw text) | Tokens |
| Parsing | Tokens | Abstract syntax tree |
| Semantic analysis | Abstract syntax tree | Annotated tree (types resolved, symbols bound) |
| Optimization | Annotated tree | Rewritten tree (more efficient form) |
| Code generation | Optimized tree | Machine instructions |
At each step, the input is more structured than what came before, and the output is more constrained than what would come from a single-pass translation.
Recently a few writers in the AI space have made the case that LLM code generation should look more like this. The argument runs roughly as follows: when you ask a model to translate natural language directly into code, you're doing single-pass compilation against an ambiguous source language. Hallucinations are the AI equivalent of miscompilation — wrong code emitted because the input admitted multiple valid interpretations and the model picked one. The fix, by analogy, is to insert an intermediate representation. Pass one transforms the natural language into a structured IR. Pass two generates code from the IR. The IR constrains the model's search space at code generation time, reducing the room for hallucination to enter.
This argument is approximately right, and it's the framing I started with when I built my pipeline. The pipeline takes my purely English utterances and a wireframe or two, and generates a markdown specification. That specification — structured English with required sections, acceptance criteria in Given/When/Then format, explicit out-of-scope declarations — is then turned into a phased execution plan stored in a structured JSON file.
The plan specifies which files each phase will create, which existing files serve as exemplars, which rule files apply, and what verification commands must pass. Then per-phase agents take the plan and generate code, working from the plan rather than from the original feature description.
Laid out this way, my pipeline roughly resembles a multi-pass compiler, but the analogy breaks at the place that matters most.
Where the analogy breaks
A real compiler's intermediate representation is a formal language with a grammar that can be mechanically parsed. Three-address code, SSA form, LLVM IR — these are unambiguous. Every well-formed program in the IR has exactly one interpretation, and the codegen pass is a deterministic function from IR to machine instructions. Given the same IR, every run produces the same machine code.
This is the point where the compiler analogy stops being descriptive and starts being misleading. A compiler's reliability comes from determinism — passes that always produce the same output given the same input. My pipeline's reliability comes from something else. It comes from how much of the meaningful decision-making has been pulled out of the runtime model and placed somewhere else.
What the pipeline actually does
Before I make the case for the harness model, it helps to have a picture of what's running. My pipeline takes a feature idea — usually expressed as a paragraph or two of prose, plus maybe a wireframe — and turns it into shipped code through three translations, each producing a more constrained representation than the last:
-
Prose to specification. A human and an AI assistant collaborate to produce a structured markdown document with explicit acceptance criteria in Given/When/Then form. This is still for human consumption — the team reviews it, debates it, signs off on it. But every "Then" clause is assertable in code, and every dependency is named.
-
Specification to plan. The signed-off markdown is mechanically transformed into a JSON file: one phase per discrete unit of work, each phase declaring exactly which files it will create, which existing files serve as conventions to follow, which rule files apply, what verification commands must pass, and which acceptance criteria it satisfies. The JSON is not for human consumption. It's for the machine. It is, frankly, miserable to read in raw form.
-
Plan to code. Each phase, in isolation, is handed to a coding agent in a fresh context. The agent reads its phase from the JSON, reads the named exemplars and rule files, writes the code, runs the verification commands, and commits.
Each step narrows the space of what can happen at the next step. The prose-to-markdown step takes a vague idea ("we need e-consents") and turns it into a list of specific behaviors that can be checked. The markdown-to-JSON step takes those specific behaviors and binds them to specific files, specific patterns, specific commands. By the time a coding agent is generating code, almost every decision that could matter has already been made — by humans, in the first two steps.
It's worth seeing what the JSON actually looks like, because the abstract claim "fully-specified intent" only lands when you see one. Here's a single phase from a real spec (slightly redacted) — the second of ten phases in a feature that adds e-consent signing for healthcare patients:
{
"id": 2,
"name": "Ecto schema and context module: PatientConsentInvitation",
"scope": "backend",
"complexity": "standard",
"acceptance_criteria": ["AC-3", "AC-4", "AC-6", "AC-9", "AC-10", "AC-11", "AC-13", "AC-15", "AC-17"],
"depends_on": [1],
"files_planned": [
"backend/***/**/*******/patient_consent.ex",
"backend/***/**/*******/invitations.ex"
],
"exemplar_files": {
"backend/***/**/*******/patient_consent.ex": "backend/example_file.ex",
"backend/***/**/*******/invitations.ex": "backend/another_example.ex"
},
"rule_files": [
"docs/rules/global.md",
"docs/rules/elixir.md",
"docs/rules/ecto.md"
],
"verification_commands": [
"cd backend && mix compile --warnings-as-errors --force",
"cd backend && mix format --check-formatted",
"cd backend && mix credo --strict"
]
}
Look at what the agent reading this entry no longer has to decide. Not which files to create — they're named. Not which patterns to follow — example_file.ex and another_example.ex are pointed to as the exact templates. Not which rules apply — they're enumerated. Not when the work is done — the verification commands draw the line. Not which acceptance criteria the phase has to satisfy — they're listed by ID, traceable back to specific Given/When/Then blocks in the spec. The agent's job is to read the named exemplars, follow the named rules, write code in the named files, and pass the named commands. That's translation. Not interpretation.
The same shape repeats across all ten phases of that spec. By the time code is being generated, the LLM is operating in the narrowest space the human could put it in.
| Step | From | To | Audience |
|---|---|---|---|
| 1 | Prose intent + wireframes | Structured markdown with Given/When/Then ACs | Humans (review, sign-off) |
| 2 | Structured markdown | JSON contract: phases, files, exemplars, rules, commands | The machine |
| 3 | JSON contract | Code, tests, commits | Reviewers (and production) |
The orchestrator that drives all three steps never writes code itself. It reads the markdown, reads the JSON, decides what runs next, and hands off to the right specialist. The specialists never see each other's working memory. Every agent gets only what it needs, in a clean context window, with a narrow tool set scoped to its job. The orchestrator's role is essentially a project manager who can't actually do any of the work — and that's the point. Reliability comes from each specialist staying narrow.
The work of writing each spec
When I write a specification for a new feature, several things have to be true for the downstream code generation to be reliable:
- The acceptance criteria have to be specific enough that they're assertable in code.
- The dependencies have to be named explicitly so phases can be ordered correctly.
- The out-of-scope section has to actually contain the things that would otherwise leak into implementation.
- The features have to be decomposed into pieces that can each be completed in a bounded session without cross-contamination.
None of this is the LLM's job. Every part of it is mine, working in collaboration with another model that's helping me draft the spec but isn't responsible for the rigor of the result. The division of labor looks roughly like this:
| What the model does | What I do |
|---|---|
| Suggests acceptance criteria | Judges whether they're concrete enough |
| Proposes a feature decomposition | Checks whether each piece has a testable exit condition |
| Flags missing dependencies | Decides which to surface in the spec versus assume from the codebase |
| Predicts what is out of scope | Validates predictions and adds what was missed |
The work on my side is analytical. It's the work of decomposing a problem into specifications rigorous enough that translation into code becomes mechanical. The model is a fast typist with good pattern recognition; I'm the one deciding what's worth typing.
The work of building it up over time
The live work of authoring a spec isn't the only register the harness operates in. Over time, recurring patterns get observed. The code review agent flags the same kind of mistake across multiple specs. A new strategy gets adopted for a particular kind of file. Tacit team knowledge — "we use Ecto.Multi for any operation that writes to multiple tables" — needs to become explicit so the pipeline can encode it for future specs.
This is the work of curating standing artifacts: rule files in docs/rules/, convention profiles for strategy-specific patterns, the spec format itself, the gate definitions. Every artifact represents prior analytical work made reusable. The artifacts only stay accurate because someone keeps doing the work of updating them as the codebase evolves.
So the harness has two registers:
| Live register | Accumulated register | |
|---|---|---|
| What it is | Analytical work done in the moment, per spec | Durable artifacts encoding prior decisions |
| What it includes | Spec authoring, judging concreteness, decomposing features | Rule files, convention profiles, spec format, gate definitions |
| When it runs | Every time you write a new spec | Once when authored, again every time it's read |
| Failure mode | Sloppy live work produces underspecified specs | Stale or missing artifacts force the live register to compensate |
Both registers matter, and they trade off against each other. The live register can compensate for gaps in the accumulated register, but only at the cost of doing more work every time. The accumulated register can compensate for sloppy live work up to a point, but only if it's been maintained.
The LLM operates inside both. It reads the spec I just wrote. It reads the rule files the team has accumulated. It looks at the exemplar files I pointed it at. It produces code. Its job is translation — taking a fully specified intent, expressed in the structured form the harness defines, and emitting code that satisfies it. When I get this right, the model's output is boring and reliable. When I get this wrong — when the spec is underspecified, when the rules don't cover the case, when the exemplar doesn't really represent the convention I had in mind — the model fills in the gaps with its training-data priors, and that's where unreliability enters.
This is the claim that "you are the harness" is meant to capture. Not that the model is unimportant, or that the artifacts are unimportant. They're both important. But the harness — the thing that actually determines whether the pipeline produces reliable code — is the human capacity for analytical decomposition and precise specification. Everything else is downstream of that.
What this looks like in practice
Two examples make the abstract claim concrete.
The first is acceptance criteria. Consider the kind of AC a thoughtful engineer might write when sketching a feature without having done the full analytical work yet:
Before: Then pagination works correctly when the client requests a specific page size.
That sentence is the kind of thing that passes informal review. It says something. It points at a real outcome. But every word in "works correctly" is doing work the implementer has to fill in. What endpoint? What query parameters? Correct how — exact row count, response structure, returned metadata? What status code? Each of these is a decision. Each decision is a place the model can pick wrong.
Compare with an actual AC from one of my specifications:
After:
- Given: an authenticated caller with
permission:xxxis assigned to 30 individuals- When: the client issues
GET /api/v1/endpoint?page=1&page_size=10- Then: the response status is 200; the response body contains exactly 10 rows; the response includes a pagination metadata object reporting
total_count: 30,page: 1,page_size: 10
Same intended outcome, expressed with no implementer-facing decisions left. The exact endpoint is named. The exact query parameters are specified. The precondition fixes the dataset size at 30. The expected status code, body shape, and metadata fields are all enumerated. The phase implementer no longer chooses anything about what "works correctly" means. It translates each clause into a test assertion or a piece of implementation code. Translation isn't a creative act in this version. It's mechanical.
The work of writing the second version is real work. It requires me to have thought through the actual intended behavior — to have decided, before any code exists, what the URL structure is, what query parameters the API exposes, what permission name gates access, what fields the pagination metadata returns and what they're called, and what concrete dataset size makes the assertion meaningful. I can't write a precise AC without first doing the analytical work of being precise. The harness, in this case, is the thinking I did to articulate those constraints. The AC text is just the artifact.
The second example is convention profiles. Early in my pipeline, the spec-builder agent would identify exemplar files for each new file in a phase and instruct the implementer to "follow the conventions" of the exemplar:
Before: Your new context module should follow the pattern of
app/lib/accounts/users.ex.
This worked, until it didn't. Pattern extraction from an exemplar is itself an interpretive act — the implementer has to decide which aspects of the exemplar are conventions to follow versus incidental details specific to the exemplar's subject matter. Different runs produced different code because different runs made different judgments about what to copy. I had inadvertently invented a system where the LLM was doing literary analysis on my Elixir files.
The fix was to stop making the implementer do pattern extraction. When my team adopts a strategy for a particular kind of file — say, "context modules use Ecto.Multi for any operation that writes to multiple tables" — that strategy gets written down once, by a human, as a convention profile:
After: Your new context module must conform to
rules/ecto-multi-context.md, which specifies:
- Public functions return
{:ok, result}or{:error, changeset}- Any function that writes to more than one table uses
Ecto.MultiEcto.Multioperations are named with descriptive atoms, not generic ones like:insert- Tests assert both the success path and the rollback behavior on partial failure
The implementer reads the profile and follows it as a specification rather than extracting it from a file. The work of writing the profile is analytical work that happens once, in a context where there's time to be careful. The work of following the profile, by an agent in a phase implementation context, is mechanical. The harness, in this case, is the thinking my team did to make tacit knowledge explicit. The profile artifact is just the output.
In both examples, the pattern is the same. Every implementer decision that I push upstream — into the spec or the rule file or the profile — is one place hallucinations can no longer enter. The work doesn't go away. It moves from the runtime agent's context to the human's context, where it can be done carefully, by someone who actually knows what the right answer is.
Building the harness over time
When I started running this pipeline, the harness was thin. Specs surfaced gaps that hadn't been anticipated. Phases blocked on conventions that weren't documented. Code review found the same kind of violation across unrelated specs. The pipeline was, to put it generously, noisy.
But the noise was the point. Every blocked phase, every recurring code-review finding, every ambiguity that surfaced during spec authoring was evidence the harness had a missing piece. The pipeline is structured to make that evidence promotable through two layers:
| Layer | What lives there | Promotion criteria |
|---|---|---|
| Memory | Code review observations, scoped to one agent | Pattern observed, captured as-is |
Rules (docs/rules/) |
Cross-cutting conventions for a file type or language | Pattern recurred across multiple unrelated specs |
Both registers of the harness — live work on each new spec, and accumulated artifacts that future specs inherit — get tighter over time, but only because someone keeps doing the work of converting observations into durable structure.
Where this leaves things
Both approaches are defensible—because everyone has opinions. My opinion is based on direct observation of near-flawless execution by an LLM agent—not on conjecture or theory. Also, this all may be irrelevent two years from now when the models' capabilities are improved by orders of magnitude.
Runtime harnesses put it downstream and try to detect it. Upstream harnesses put it earlier and try to prevent it. Whether either bet is right for your team depends on context, and a skilled engineer can judge from the task at hand which approach fits. A small bug fix probably doesn't warrant the full pipeline. A feature with cross-cutting architectural implications almost certainly does.
What I want to leave you with isn't a recommendation to build my pipeline. It's an invitation to look at your own setup and ask a different question than "what's my model doing wrong?" Ask instead: where do the meaningful decisions in my pipeline currently live?
- In rule files I can curate?
- In specs I can write carefully?
- In tacit knowledge I haven't documented?
- In the model's training-data priors?
The first three are places I can improve by doing analytical work. The fourth is a place I can't reach. The harness is the work of moving decisions out of the fourth and into the first three.
That work is yours to do. The model just translates.